"R 기초 - 그 1 -
시작 → 프로그램"
R의 프롬프트( > )에 "q( )"를 입력하면 세션이 종료됩니다.
"설치 디렉토리의 etc에 있는 Rconsole 파일의 70번째 줄에서 language = EN으로 설정하면 메시지가 영어로 변경된다."

인터프리터형 언어
- 프롬프트에 함수를 입력하면 결과를 얻을 수 있다
- 함수 사용법을 모를 때는
> help(log) 또는 > ?log 를 입력하면 온라인 도움말을 사용할 수 있다.
형(정수, 실수 등)에 구애받지 않고 혼합 사용 가능하지만, 문자열과 숫자는 구분해야 한다.
x에 6을 대입(선언 불필요)하고, 변수명만 입력하여 내용을 표시. y에 7을 대입.
+, -, *, / 는 일반적으로 사용할 수 있다.
계산 결과를 z에 대입.
한번 사용한 변수라도 내용 변경, 형 변경 모두 가능.

객체 저장
- R에서는 데이터나 함수 모두를 객체라고 부른다
→ R은 객체 지향 언어*이다 - 객체는 세션 종료 시 저장해두면, 이후에도 계속해서 사용할 수 있다.
*데이터와 그 데이터를 조작하는 절차를 객체라는 하나의 단위로 통합하여, 객체의 조합으로 프로그램을 작성하는 프로그래밍 기법.
프로그램의 일부를 재사용하기 쉬운 등의 장점이 있다.
대표적인 객체 지향 언어로는 C 언어에 객체 지향적인 확장을 추가한 C++이 잘 알려져 있다.

오브젝트와 프레임

R에서의 형(Mode)
- 빈 값(NULL) "null"
- 논리값 "logical" (→ TRUE 또는 FALSE)
- 실수 "numeric"
- 복소수 "complex"
- 문자열 "character"

원자 오브젝트에서 복잡한 데이터로
- 원자 오브젝트를 결합하여 더 복잡한 대상을 표현한다.
- 정의된 클래스에 대해 함수를 정의한다.
| 벡터, 행렬이 시계열 속성 (시작 시기 등)을 가질 경우 |
시계열 ts() | 자기상관계수, 시계열 모델 |
| 벡터가 행 수, 열 수라는 추가적인 속성을 가질 경우 |
행렬 matrix() | 역행렬, 고유값 |
| 여러 실수의 집합 | 벡터 c() | 최대값, 최소값, sort |
| 원자 오브젝트 (atomic object) |
실수 |

벡터의 표현
함수 c( )는 인수를 결합하여 벡터로 만듭니다.
이 경우 길이가 3인 벡터가 생성됩니다.
문자열 벡터도 가능합니다.
함수 log()에 인수가 주어졌을 때, 각 요소에 대해 로그를 계산합니다.
이 경우, x에 대입도 이루어지며 값은 남아 있습니다.
'n1:n2'라는 표기법으로 n1에서 n2까지의 수열을 생성할 수 있습니다.
인덱스 집합 벡터 등을 생성할 때 유용합니다.
연산자 ^는 거듭제곱 계산을 수행하며, 이 또한 각 요소에 적용됩니다.
연산자 +는 모든 요소에 동시에 3을 더할 수 있습니다.
다른 형(벡터와 스칼라) 간에도 연산이 가능합니다.

벡터와 함수

벡터의 요소의 지정

그 외의 벡터에 관한 함수

행렬의 표현
- 데이터 자체는 내부적으로 벡터로 처리됩니다.
- 2차원 배열로서, 행 수와 열 수를 지정해 줍니다.
- 오브젝트의 속성으로 행과 열의 이름을 가질 수 있습니다.

행렬의 요소의 지정

함수 dimnames()의 사용
이름이 없는 상태에서는 기본적으로 행과 열 번호가 표시됩니다
(리스트가 무엇인지는 다음 시간에 설명합니다.)
함수 dimnames()를 사용하여 행이나 열에 이름을 붙일 수 있습니다.
var(x)는 x가 행렬일 때 분산-공분산 행렬을 계산합니다.
각 열에 이름이 있으면 결과에도 이름이 자동으로 상속됩니다.
dimnames()를 대입하지 않고 사용하면 행과 열의 이름(속성)을 표시해줍니다.
[[1]]은 첫 번째 축(행 방향), [[2]]는 두 번째 축(열 방향)의 속성을 나타냅니다.

행렬에 관련된 연산자와 함수
기타 QR 분해 **qr()**, 코레스키 분해 **chol()**, 특이값 분해 **svd()** 등의 함수가 행렬에 관련됩니다.

파일에서 데이터 입력 (1)
- 함수 scan()을 사용합니다.

파일에서 데이터 입력 (2)
- scan() 함수를 사용하여 CSV 형식의 데이터를 읽어들입니다.
- 파일 이름은 자신의 환경에 맞게 변경합니다.

파일에서 데이터 입력 (3)
- 표 형식의 데이터가 주어지면 read.table() 또는 read.csv() 함수를 사용할 수 있습니다.

그래픽스
- 고수준 그래프 함수 (high-level plots)
- 함수: plot(), hist(), pie(), barplot() 등
- 그 외의 함수는 도움말의 'High-Level Plots'을 참조
- 저수준 그래프 함수 (low-level plots)
- 그래프에 선을 추가하거나, 후에 점을 찍는 등의 작업
- abline(), title() 등

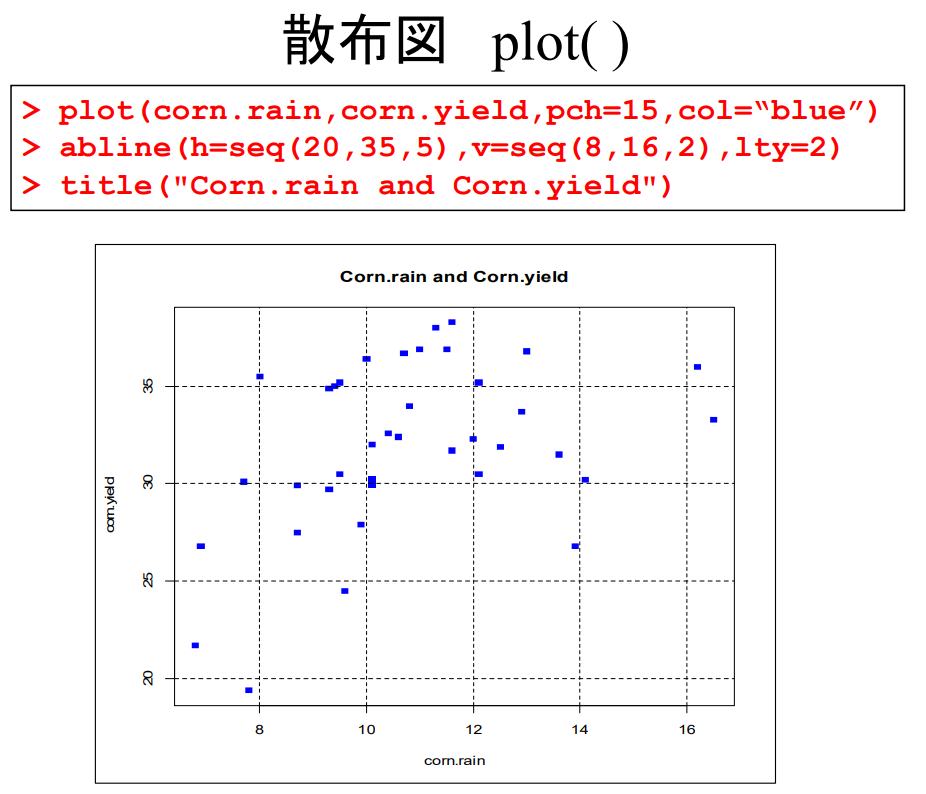
산포도 plot( )
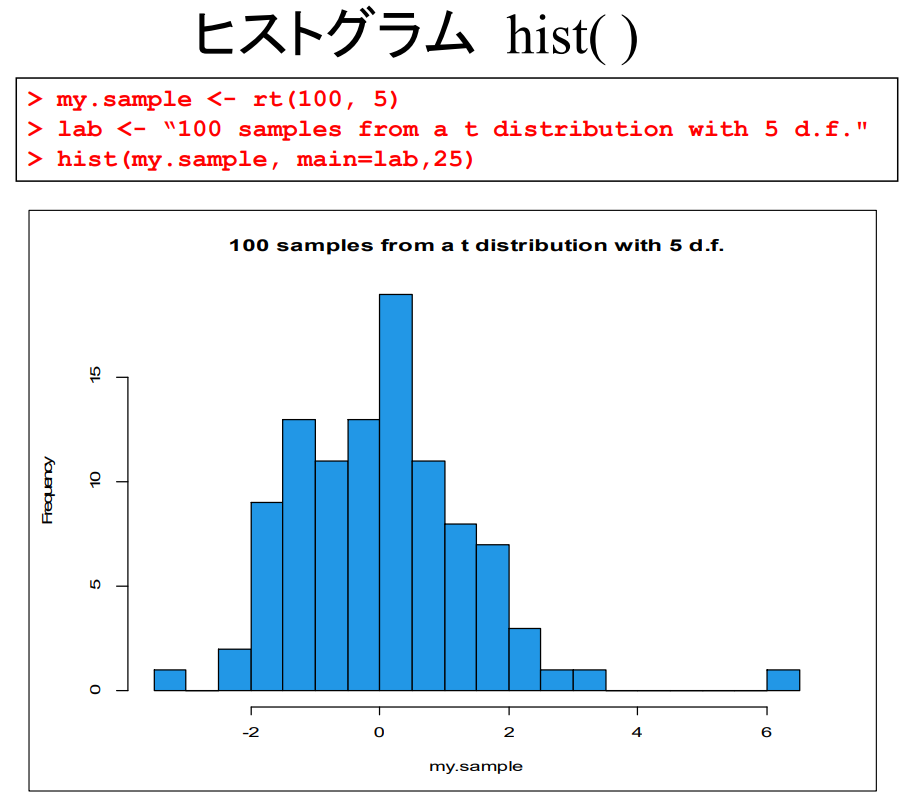
히스토그램 hist( )
과제 1. R에서 처리 실행
- CSV 형식의 파일을 읽어와 R 오브젝트로 만든다.
- (1) 매출액, 당기순이익의 평균과 표준편차를 구한다. (mean(), sd() 함수 사용)
- (2) ROE를 계산하고, 히스토그램을 그려본다. (hist() 함수 사용)
- (3) 전기 기기(일경 업종 코드 123221~123229)에 대한 ROE 평균을 계산한다.

2번 ROE 계산은 ROEt = NIt / BVt 로 해도 무방
원래는 BVt-1로 해야함
2번은 outlier를 어떻게 처리할지 고민
워드로 하던지 pdf로 제출
'WBS - 2024 Fall > 포트폴리오 매니지먼트' 카테고리의 다른 글
| (PF Mgmt #8) (8) Fama-MacBeth형 회귀 분석 (0) | 2024.11.29 |
|---|---|
| (PF Mgmt #7) (7) 포트폴리오 방법을 이용한 정보 분석 (0) | 2024.11.22 |
| (PF Mgmt #6) (6) 제약 조건이 있는 포트폴리오 최적화 (0) | 2024.11.15 |
| (PF Mgmt #5) (5) 평균-분산 모델의 수리 (0) | 2024.11.08 |
| (논문1) 기대 주식 수익률의 횡단면 유진 F. 파마와 케네스 R. 프렌치 | The Cross-Section of Expected StockReturns EUGENE F. FAMA and KENNETH R. FRENCH (0) | 2024.10.28 |
| (PF Mgmt #4) (4) 시계열 데이터와 데이터베이스 접근 (0) | 2024.10.25 |
| (PF Mgmt #3) (3) R의 기초 - 그 두 번째 (0) | 2024.10.21 |
| (PF Mgmt #1) Introduction - 문헌조사의 방법 (0) | 2024.10.04 |



