기업경제학 실습 제4회

오늘의 일정
- 데이터 집계 방법: R로 데이터 정리하기
- 이상치 처리
- 선형 회귀 모델(2)
- 변수의 단위
- 누락변수 편향에 대하여
참고 문헌: 모리타 카『실증분석입문』일본평론사, 2014년

업종별 또는 연도별 평균값
- 샘플을 특정 그룹으로 분류하고, 각 그룹별로 평균값 등을 계산할 때 group_by ( ) 라는 명령을 사용한다.
- 패턴 1
test_group %>%
filter ( TCLS < 7000 | TCLS >= 8000 ) %>%
group_by ( TCLS ) %>%
summarize (
n=n(),
mean_ROA_0 = mean ( ROA_0 , na.rm = TRUE )
) - 패턴 2 : mean_ROA_0_i 에 이름을 변수로 추가한다.
mean_ROA_0_i <- test_group %>%
filter ( TCLS < 7000 | TCLS >= 8000 ) %>%
group_by ( TCLS ) %>%
summarize (
n=n(),
mean_ROA_0 = mean ( ROA_0 , na.rm = TRUE )
)
kable ( mean_ROA_0_i )
- 패턴 1

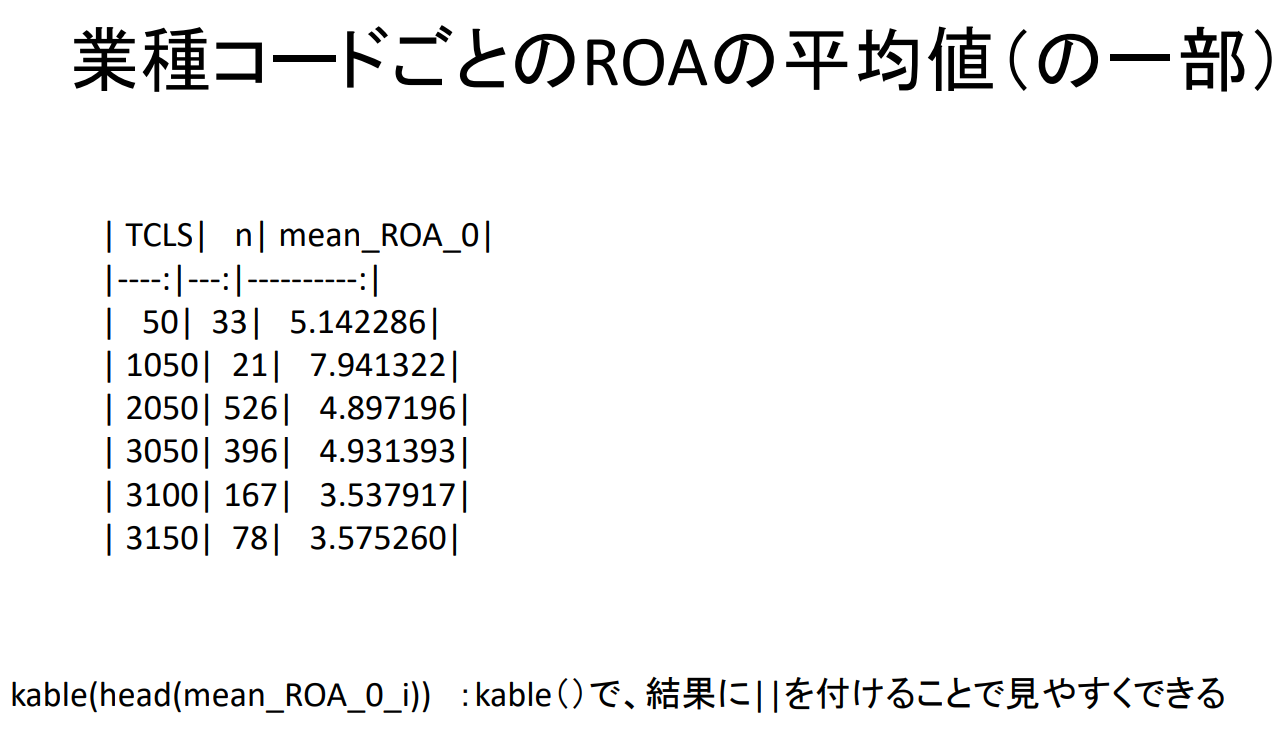
업종 코드별 ROA 평균값(일부)
kable ( head ( mean_ROA_0_i ) ) : kable ( ) , 결과에 | | 를 붙여서 보기 쉽게 할 수 있습니다.
샘플을 부분적으로 꺼내는 방법
- 여기서 샘플 중 업종코드(TCLS) 중 7000번대 이외의 데이터만 사용하고 싶다고 가정해보자
- 이 경우 두 가지 방법이 있다.
1) tidyverse를 전제로 하는 방법:
filter ( TCLS < 7000 | TCLS >= 8000 )
| = or
샘플 코드에서는 이 방법 사용
→ 코드 예시에서는 여기를 사용
(2) package를 필요로 하지 않는 방법:
subset ( TCLS < 7000 | TCLS >= 8000 )

데이터 집계
group_by ( TCLS ) % > %
- 각 산업별로 데이터를 집계하고 싶다고 하자.
→ 이 경우 deplyr 패키지를 이용한 방법이 편리하다 (deplyr는 tidyverse에 포함되어 있다). - group_by ( TCLS ) : 에서 산업 코드별로 샘플을 그룹화한다.

데이터 집계
summarize ( )
- 이 함수로 집계 방법을 지정한다.
- n = n ( ) : 각 그룹(산업)별 샘플 수를 나타낸다.
mean_ROA_0 = mean ( ROA_0 , na.rm = TRUE )
mean_ROA_0 : 작성하는 변수의 이름
ROA_0 : Original 변수 이름
- mean ( ) : ( ) 안의 변수(여기서는 ROA)의 평균값을 계산한다.
- 평균값을 계산할 때, 샘플 내에 결손값이 있으면 계산이 불가능하다.
→ 그래서 na.rm = TRUE 로 결손값을 무시하도록 지시한다. - sd ( ) 로 표준편차, median ( ) 으로 중앙값을 구한다.

파이프 연산자 정보
- R의 표준 함수가 아닌 dplyr(tidyverse에 포함된)을 사용하는 장점 중 하나는
[ % > % ] ( 파이프 연산자(pipe) )를 사용할 수 있다는 점이다. - 파이프를 사용하면 함수에 의한 처리를 순서대로 연결하여
중간 데이터를 거치지 않고 여러 처리를 한꺼번에 할 수 있다.

파이프 연산자 정보
- 예를 들어, 앞의 코드에 대해 파이프를 사용하지 않으면,
1) mean_ROA_0_i1 <- filter ( test_group, TCLS <7000 | TCLS >= 8000 )
2) mean_ROA_0_i2 <- group_by ( mean_ROA_0_i1 , TCLS )
3) mean_ROA_0_i3 <- summarize ( mean_ROA_0_i2 , n=n() , mean_ROA_0 = mean ( ROA_0 , na.rm = TRUE ) )
→ 중간 과정에서도 하나하나 파일명을 붙이고 있다.

파이프 연산자 정보
- 파이프를 사용하면,
mean_ROA_0_i <- test_group % > %
filter ( TCLS < 7000|TCLS >= 8000 ) % > %
group_by ( TCLS ) % > %
summarize(
n = n ( ) ,
mean_ROA_0 = mean ( ROA_0 , na.rm = TRUE )
)

이상치 처리에 대하여
- OLS는 잔차제곱합 최소화
→ 추정결과가 이상값의 영향을 받기 쉬움
→ 이상치를 처리하는 것이 중요해진다.
→ 다만, 이상치를 어떻게 처리하느냐에 따라 결과가 크게 달라질 수 있다.
→ 흔히 사용되는 것이 Winsorizing. - 이는 분포의 95%(이 수치는 변경 가능) 이상 혹은 5%(이 수치는 변경 가능) 이하의 모든 값을
95% 분위점 혹은 5% 분위점과 동일한 값으로 변환하는 기법

이상치 처리에 대하여

- 이제 다음과 같은 벡터, a, 를 생성한다.
a <- c ( 92, 19, 101, 58, 1053, 91, 26, 78, 10, 13, -40, 101, 86, 85, 15, 89, 89, 28, -5, 41 )

- a의 winsorize는 DescTools 패키지를 사용하여
a_new <- Winsorize ( a , probs = c ( 0.05 , 0.95 ) )
- 결과는
c ( 92, 19, 101, 58, 148.60, 91, 26, 78, 10, 13, -6.75, 101, 86, 85, 15, 89, 89, 28, -5, 41 )


이상치 처리에 대하여
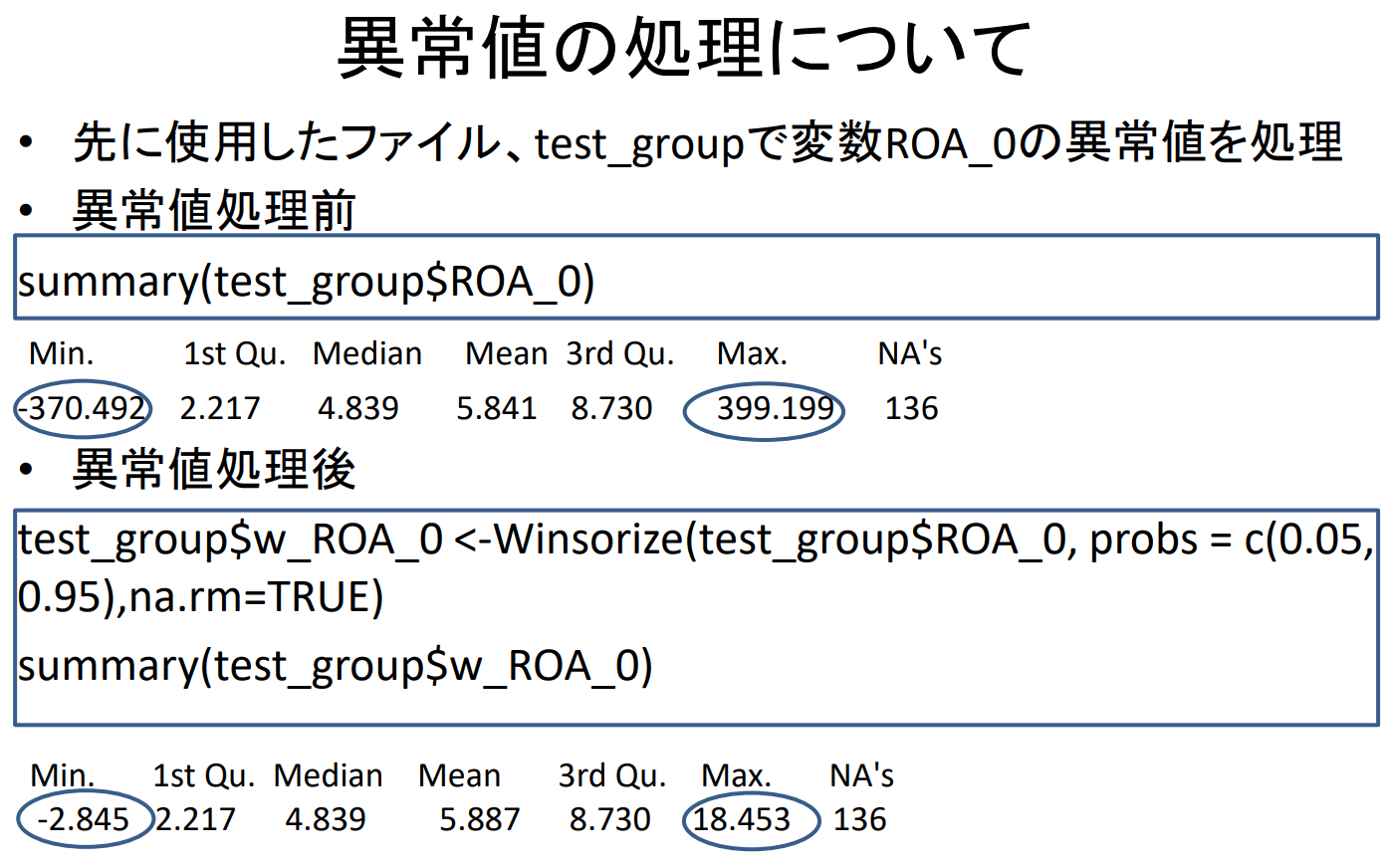
- 앞서 사용한 파일, test_group에서 변수 ROA_0의 이상값 처리
- 이상값 처리 전

summary ( test_group$ROA_0 )
| Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. | NA's |
| -370.492 | 2.217 | 4.839 | 5.841 | 8.730 | 399.199 | 136 |

- 이상치 처리 후
test_group$w_ROA_0 <- Winsorize ( test_group$ROA_0 , probs = c ( 0.05 , 0.95 ) , na.rm = TRUE )
summary ( test_group$w_ROA_0 )
| Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. | NA's |
| -2.845 | 2.217 | 4.839 | 5.887 | 8.730 | 18.453 | 136 |
변수 단위
- 정부 통계로 공개된 전국 1750개 시군구 데이터를 이용,
'실업자가 많은 시군구일수록 범죄 건수가 많다'는 가설을 검증한다. - 설명변수 X로 실업자 수
- 피설명변수(목적변수)로서 범죄 건수
※ 이 데이터는 모리타카『실증분석입문』일본평론사(日本評論社)의 서포트 페이지에 있다.
https://sites.google.com/site/empiricallegalstudy/home

데이터 불러오기
- 파일명은 criminal.csv를 사용한다.
crimes <- read.csv ( "criminal.csv" , header = TRUE )
- 변수는 다음과 같다,
id: 지자체 ID 번호
crime: 범죄 건수
unemp: 실업자 수
pop: 인구

회귀분석
E ( 𝑌 | 𝑋 ) = 𝛽₀ + 𝛽₁ 𝑋
→ 범죄를 유발하는 요인으로 실업자수(X)만 다루고 있다.
→ 하지만 범죄 건수(Y)에 영향을 미치는 다른 요인도 있을 것이다.
→ 그래서 다른 요인들을 모아 오차항 u로 처리한다.
→ 표준적인 선형회귀모형의 식이 된다.

R을 이용한 OLS
- 다음 명령을 입력합니다.
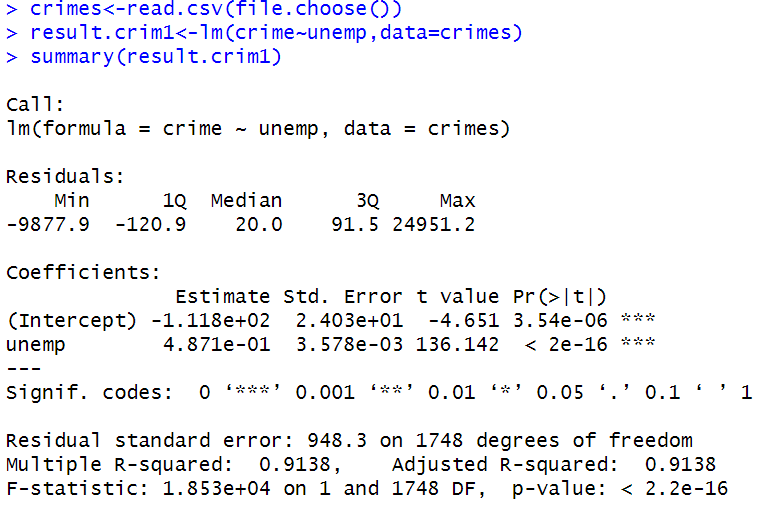
result.crim1 <- lm ( crime ~ unemp , data = crimes )
summary ( result.crim1 )

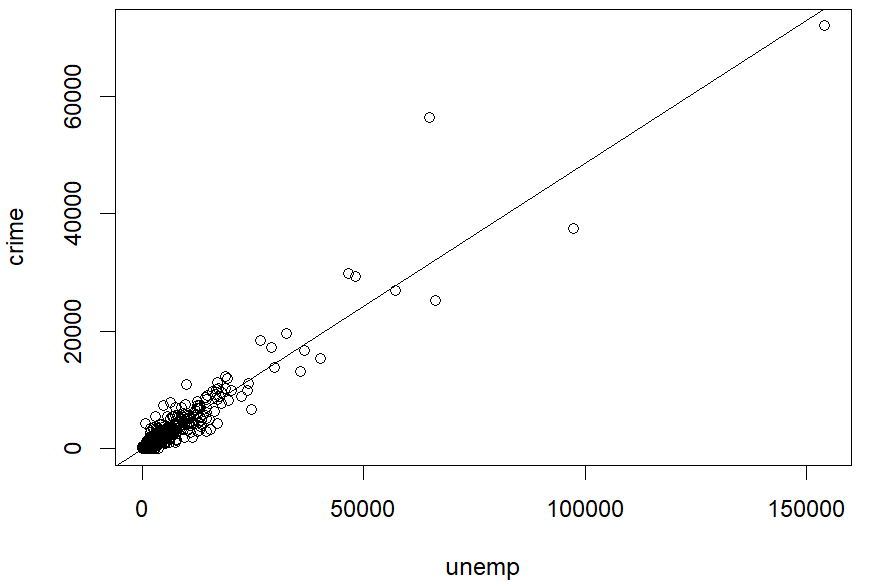
plot ( crime ~ unemp , data = crimes )
abline ( result.crim1 )


R을 이용한 OLS
- 다음 명령을 입력합니다.

base.plot <- ggplot ( crimes, aes(x = unemp, y = crime) ) + geom_point ( )
base.plot + stat_smooth ( method = "lm", se = FALSE, colour = "black", size = 1 )


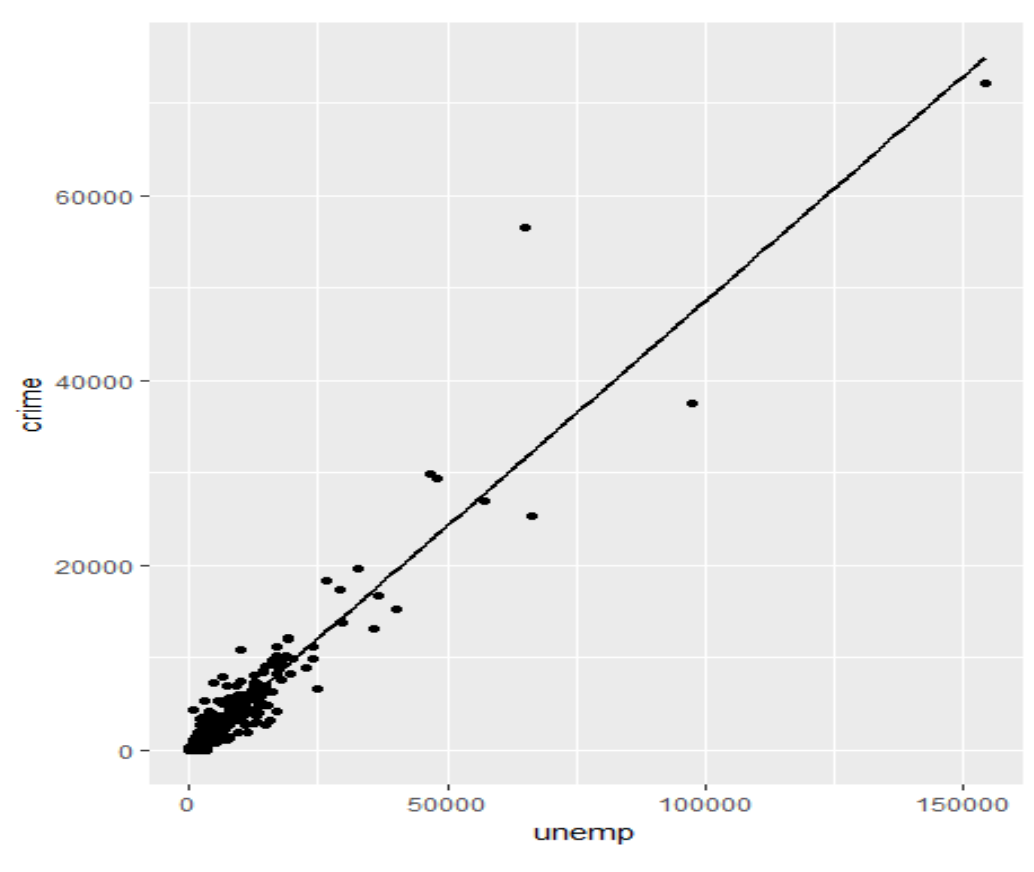

추정 결과
- 위의 분석 결과에서 Y = -112 + 0.487 X
이 공식을 어떻게 해석해야 하는지
ΔY / ΔX = 0.487
ΔX:X의 변화분, ΔY:Y의 변화분
→ 실업자 수(X)가 1명 증가하면 범죄 건수(Y)는 0.487건 증가
→ 실업자 수(X)가 1,000명 증가하면 범죄 건수(Y)가 487건 증가

결정계수
잔여 표준오차: 1748 자유도 기준, 948.3
Multiple R-squared: 0.9138,
Adjusted R-squared: 0.9138
→ 실업률의 변화(X)로 범죄 건수(Y)의 91%를 설명할 수 있다.

설명변수의 스케일링
- 지금 범죄건수(Y)와 실업률(X)의 관계를 보면
Y = -112 + 0.487 X - 범죄건수(Y) 단위를 1건에서 100건으로 한다.
→ 피설명변수(Y)를 0.01배로 한다.
→ 결과는 어떻게 달라질까?

새로운 변수를 만드는 방법
- 범죄 건수(Y) 단위를 100건으로
→ 범죄 건수(Y)에 0.01을 곱한다.
crimes$crimea <- crimes$crime*0.01
- 새로운 변수의 이름이 crimea
- crimea는 crime*0.01, 즉 범죄 건수(crime)에 0.01을 곱하여 만들어진다.

result.crim2 <- lm ( crimea ~ unemp , data = crimes )
summary ( result.crim2 )

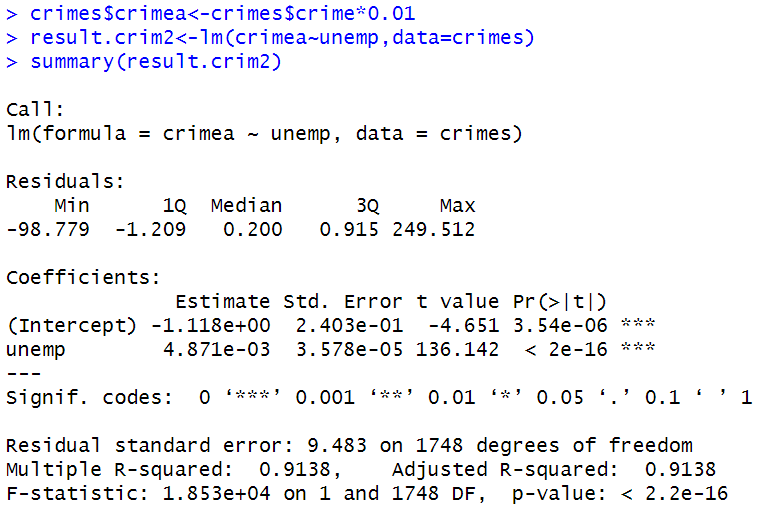
Call:
result.crim2 <- lm ( crimea ~ unemp , data = crimes )
summary ( result.crim2 )
Y = -1.12 + 0.00487 X

피설명변수의 스케일링
- 일반적인 표현으로는 피설명변수(Y)를 c배로 하면 절편과 계수 모두 c배가 된다.
𝑦 = 𝛼 + 𝛽𝑥 + u
→ 𝑐𝑦 = 𝑐𝛼 + (𝑐𝛽)𝑥 + 𝑐u
R^2에 영향 없음

설명 변수(X)의 스케일링
- 지금 범죄 건수(Y)와 실업률(X)의 관계를 보면
𝑌 = −112 + 0.487𝑋 - 실업자 수(X)의 단위를 1건에서 100건으로 한다.
→ 설명변수(X)를 0.01배로 한다.
→ 결과는 어떻게 될까?

새로운 변수를 만드는 방법
- 실업자 수(X)의 단위를 100건으로
→ 실업자 수(X)에 0.01을 곱한다.
crimes$unempb <- crimes$unemp*0.01
- 새로운 변수의 이름이 unempb
unempb는 unemp*0.01, 즉 실업자 수(unemp)에 0.01을 곱하여 만들어진다.

result.crim3 <- lm ( crime ~ unempb , data = crimes )
summary ( result.crim3 )
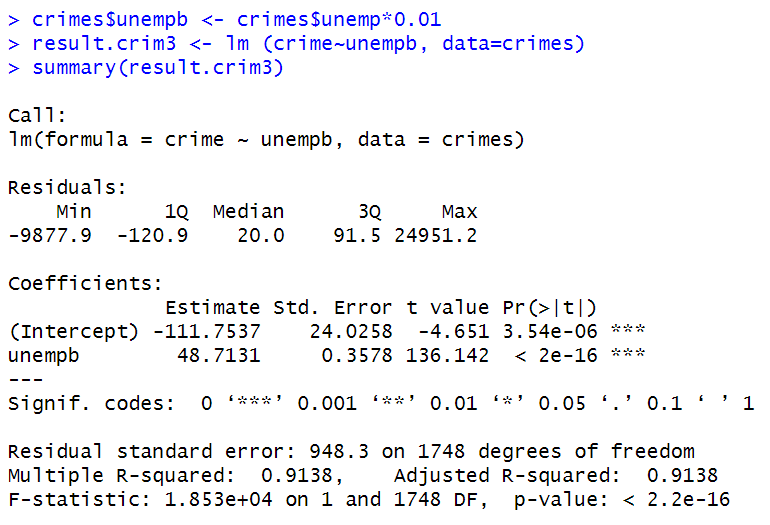

설명 변수(X)의 스케일링
- 좀 더 일반적인 표현으로 설명변수(X)를 c배로 하면 계수가 (1/c)배로 증가한다.
𝑦 = 𝛼 + 𝛽𝑥 + 𝑢
→ 𝑦 = 𝛼 + ( 𝛽 / 𝑐 ) 𝑥 + 𝑢
R2에 영향 없음

선형 회귀 모델의 중요한 가정
- 관측 불가능한 오차항(u)과 설명변수 x의 관계에 대하여
𝐸 ( 𝑢𝑖 | 𝑥𝑖 ) = 𝐸 ( 𝑢𝑖 ) = 0
→ 임의의 변수 x에 대해 오차항 u의 값은 일정하고 제로
= Zero Conditional mean independence(CMI)

선형 회귀 모델의 중요한 가정
wage𝑖 = 𝛼 + 𝛽 × education𝑖 + 𝑢𝑖
이 모델에서 𝐸 ( 𝑢𝑖 | 𝑥𝑖 ) = 𝐸 ( 𝑢𝑖 ) = 0 의 의미를 생각하다
- 교육 외에 임금에 영향을 미치는 요인으로 '개인이 선천적으로 가지고 있는 능력'이 있다고 하자.
→ u의 내용은 관찰 불가능한 '능력'이라고 가정한다
(실제로는 그 외에도 많은 요인이 있지만, 여기서는 단순화를 위해 한 가지 요인만 고려한다).

선형 회귀 모델의 중요한 가정
- 이제 u = ability 라고 하자,
𝐸 ( 𝑢𝑖 | 𝑥𝑖 ) = 𝐸 ( 𝑢𝑖 ) = 0
의 가정은 예를 들어 다음이 성립한다는 것을 의미한다.
𝐸 ( ability | 12 ) = 𝐸 ( ability | 16 ) = 𝐸 ( ability )
12년 교육을 받은 사람도, 16년 교육을 받은 사람도 같은 '능력'을 가진다.
→ '능력'이 높은 사람일수록 더 오래 교육을 받는다는 가능성 배제

자본 구성의 문제로 생각해보자
- 수익성(ROA)과 부채비율(Lev)의 관계를 생각해보고 싶다.
Lev𝑖 = 𝛼 + 𝛽 × ROA𝑖 + 𝑢𝑖 - CMI의 가정이 충족된다는 것은 어떤 의미일까?
→ 모든 ROA 수준에 대해 평균 u는 같은 값을 취한다. 𝐸 ( 𝑢𝑖 | ROA𝑖 ) = 𝐸 ( 𝑢𝑖 )
→ 이 가정이 성립한다고 봐도 될까?

자본 구성의 문제로 생각해보자
- 추정 모델 Lev𝑖 = 𝛼 + 𝛽 × ROA𝑖 + 𝑢𝑖 에서 '경영자의 능력의 높이'는 u 에 포함된다.
- 이 모델은 '경영자의 능력의 높낮이'는 ROA와 독립적이라고 가정
⇔ 실제로는 '경영자의 능력이 높은 기업' 일수록 ROA가 높을 가능성
𝐸 ( 𝑢𝑖 | ROA𝑖 ) ≠ 0

누락된 변수 바이어스
- 설명변수에 포함되지 않은 '능력의 높음'의 영향이 문제가 된다.
→ 누락된 변수의 문제(omitted variable problem)
→ 이 문제를 해결하기 위해서는 설명변수에 '능력의 높이'를 나타내는 변수를 추가하면 된다
(단, 그것이 관찰 가능하다면).

누락된 변수 문제
- 설명변수(x)와 상관관계를 가지면서 동시에 피설명변수(y)에 영향을 미칠 수 있는 요소를
오차항이 포함 (A)하고 있는 경우, 설명변수(x)와 오차항(u)이 상관관계를 가진다.
⇒ 이 경우 OLS 추정량은 일치하지 않는다.
⇒ 이것이 '결측변수 문제'이다. - 누락변수의 문제를 일으키는 변수를 교란요인(confounding factor)이라고 한다.

누락된 변수 바이어스(omitted variable bias)
- 이제 다음과 같은 모델을 생각해보자.
log 𝑊𝑖 = 𝛽₀ + 𝛽₁ 𝑆𝑖 + 𝛽₂ 𝐴𝑖 + 𝑢𝑖
𝐸 [ 𝑢𝑖 | 𝑆𝑖 , 𝐴𝑖 ] = 0
단, W는 임금, S는 교육연수, A는 능력
- A(능력)를 고정한 상태에서 S(교육연수)만 1년 늘리면 logW(임금)의 조건부 기대치는 β₁만큼 상승한다.
→ 능력을 통제하고, 교육연수를 1년 늘리면, 임금의 기대값은
→ 이것을 이제 '교육의 수익률'이라고 부른다.

누락된 변수 바이어스(omitted variable bias)
- 이제 앞의 모델 대신
log 𝑊𝑖 = 𝛼₀ + 𝛼₁ 𝑆𝑖 + 𝑣𝑖
𝐸 [ 𝑣𝑖 | 𝑆𝑖 ] = 0
를 추정하면, 𝛼₁ 의 추정량은
𝛼₁ = Cov ( logWi , Si ) / Var ( Si )
logWi = 𝛽₀ + 𝛽₁ Si + 𝛽₂ Ai + ui를 대입하면,
𝛼₁ = 𝛽₁ + 𝛽₂ { Cov ( Si , Ai ) / Var ( Si ) } ← Plus가 예상되기 때문에
→ 단회귀 모형은 교육 수익률을 과도하게 추정한다. → 누락변수 편향


DAG의 설명
이 그래프를 DAG(Directed Acyclic Graphs: 비순환적 지향성 그래프)라고 한다.
| 설명변수 S(교육연수) |
피설명변수 logW(임금) |
| ↖↗ A(능력) 교란요인 (Confounding Factor) |
|
S ← A → logW : 이를 DAG에서는 Backdoor path라고 부른다.

중복 제어 변수
- 통제변수를 너무 많이 넣으면 어떻게 될까?
𝑦𝑖 = 𝛽₀ + 𝛽₁ 𝑥₁𝑖 + 𝛽₂ 𝑥₂𝑖 + 𝛽₃ 𝑥₃𝑖 + 𝑢𝑖
𝐸 [ 𝑢𝑖 | 𝑥₁𝑖, 𝑥₂𝑖, 𝑥₃𝑖 ] = 0
→ 𝛽₁ 의 추정에 관심이 있는 반면, 올바른 모델은 다음과 같다고 가정한다.

중복 제어 변수
- 통제변수를 너무 많이 넣으면 어떻게 될까?
𝑦𝑖 = 𝛽₀ + 𝛽₁ 𝑥₁𝑖 + 𝛽₂ 𝑥₂𝑖 + 𝛽₃ 𝑥₃𝑖 + 𝑢𝑖
를 OLS로 추정해도 큰 문제가 발생하지 않습니다.
- 𝛽₁ 의 OLS 추정량은 두 모델 모두에서 동일한 일치 추정량을 보인다.
- 𝛽₃ 의 일치 추정량은 0으로 수렴한다.
- 다만, 불필요한 통제변수를 넣으면 추정량의 분산이 커지는 경우가 있다.
- 전반적으로 통제변수를 너무 많이 넣는 폐해는 그리 크지 않다.

다음 글
- 더미 변수를 이용한 분석
- 변수 선택의 문제

'WBS - 2023 Fall > 기업경제학 연습' 카테고리의 다른 글
| (기업경제 #9) Matching (0) | 2023.12.06 |
|---|---|
| (기업경제 #8) 로지트 모델(Logit Model)과 프로빗 모델(Probit Model) (0) | 2023.11.29 |
| (기업경제 #7) DID | Difference-in-Difference (차이의 차이 분석) (0) | 2023.11.16 |
| (기업경제 #6) 패널 분석 (Panel data analysis) (0) | 2023.11.09 |
| (기업경제 #5) 더미 변수를 이용한 분석 (0) | 2023.11.02 |
| (기업경제 #3) 선형회귀 Model (0) | 2023.10.19 |
| (기업경제 #2) (0) | 2023.10.12 |
| (기업경제 #1) (0) | 2023.10.05 |



