기업경제학 실습: 제9회

오늘의 일정
- 매칭(1)
참고 문헌:
Cunningham, S. 2021. Causal Inference. Yale University Press.
Ho,D., Imai,K., King,G., E. A. Stuart.2011. MatchIt: Nonparametric Preprocessing for Parametric Causal Inference.
야스이 쇼타 주식회사 호쿠소엠 '효과 검증 입문' 기술평론사, 2020년
호시노 다카히로(星野嵩宏)「통계적 인과효과의 기초」岩波データサイエンスVol.3, 62- 89, 2016년
森田果『실증분석입문:데이터에서 '인과관계'를 읽는 법』일본평론사, 2014년
Pearl,J., Glymour,M., and N.P.Jewell, 『입문 통계적 인과추론(Causal Interence in Statistics: A Premier)』아사쿠라서점, 2019년
고려해야 할 문제
- 기업행동, 예를 들어, 'M&A를 실시하는 것'이 기업의 성과 등에 어떤 영향을 미쳤는지를 평가하고 싶다.
→ 이는 기업행동과 그 영향에 대한 '인과관계 추정의 문제'로 볼 수 있다.
→ 이 작업을 할 때 가장 큰 문제는 무엇인가?
고려해야 할 문제
- M&A의 인과관계는 다음과 같이 잠재적 결과의 차이로 정의된다.
- M&A의 인과효과 =
'M&A를 실시했을 경우 기업의 실적'
마이너스
'M&A를 실시하지 않았을 경우의 기업의 실적'
고찰할 문제
- 우리가 관찰할 수 있는 것은,
- 'M&A를 실시한' 케이스
- 'M&A를 실시하지 않은' 케이스
둘 중 하나만 관찰할 수 있다.
- '관찰할 수 있는 것은 잠재적 결과(potential outcome) 중 하나뿐이며,
현실적으로 발생하지 않은 잠재적 결과(=이를 반사실(counterfactual)이라고 부른다)는 관찰할 수 없다. - '반사실은 관찰할 수 없다'는 한계 하에서 인과효과를 추정하려면 어떻게 해야 하는가?
처리군(treatment firms)과 대조군(Control firms)
- 문제 삼고 있는 '행동'을 취했는지 여부 외에는 가능한 한 동일한 특징을 가진 표본기업을 찾아 비교한다.
- 분석대상 행동(M&A 등)을 취한 샘플: 처리군(treatment firms)
- 비교대상 샘플: 대조군(control firms)
관찰 데이터로 RCT에 가까운 상태를 만드는 방법
- 잠재적 결과에 영향을 미치는 요인은 문제 삼고 있는 행동(처치) 이외에도 다수 존재한다.
- 이러한 요소들은 회귀분석에서는 설명변수에 해당하며, 인과효과 추정에서는 공변량(covariate)이라고 한다.
- '치료군'과 '대조군' 사이에 중요하다고 생각되는 공변량에 대해 '균형이 맞는다면',
두 그룹의 관찰 결과의 차이를 살펴봄으로써 평균적인 인과효과를 추정할 수 있다.

담배 사용자 1000명당 사망률
| 연령층 | 종이 담배 | 이용자비율 | 시가 | 이용자비율 |
| 젊은층 | 4% | 40% | 2% | 10% |
| 중년 | 8% | 30% | 6% | 30% |
| 노년 | 30% | 30% | 25% | 60% |
| 평균사망률 | 13% | 100% | 17% | 100% |
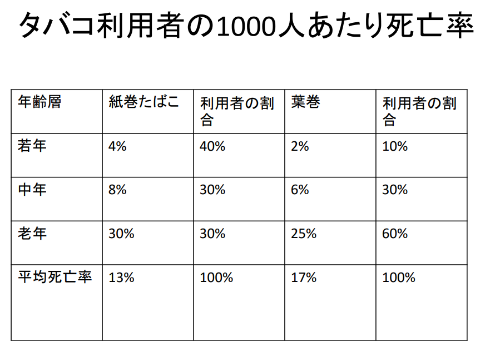
담배 사용자 1000명당 사망률
- 단순히 평균 사망률의 차이를 보면 시가의 사망률이 더 높다 ( 13% vs 17% )
- 그러나 이용자 비율은 시가의 경우 고령층에 편중되어 있다.
→ 위의 단순 평균에서는 연령이 '누락변수 편향'을 낳고 있다.
→ 연령은 교란요인(confounder)이라고 한다.

계층화(Subclassification)에 의한 통제
- 종이담배 / 시가의 흡연과 ( D = 1 or 0 ) 과 사망률의 관계를 분석하고자 한다.
- D → Y : 알고 싶은 인과관계
- 이때 연령(A)이 사망률(Y)과 흡연 경향(D)에 영향을 미친다.
- D ← A → Y : 이를 DAG에서는 Backdoor path라고 부른다.
- A가 교란요인이므로 분석에 있어서는 통제해야 함
이 그래프를 DAG ( Directed Acyclic Graphs: 비순환적 지향성 그래프 )라고 한다.
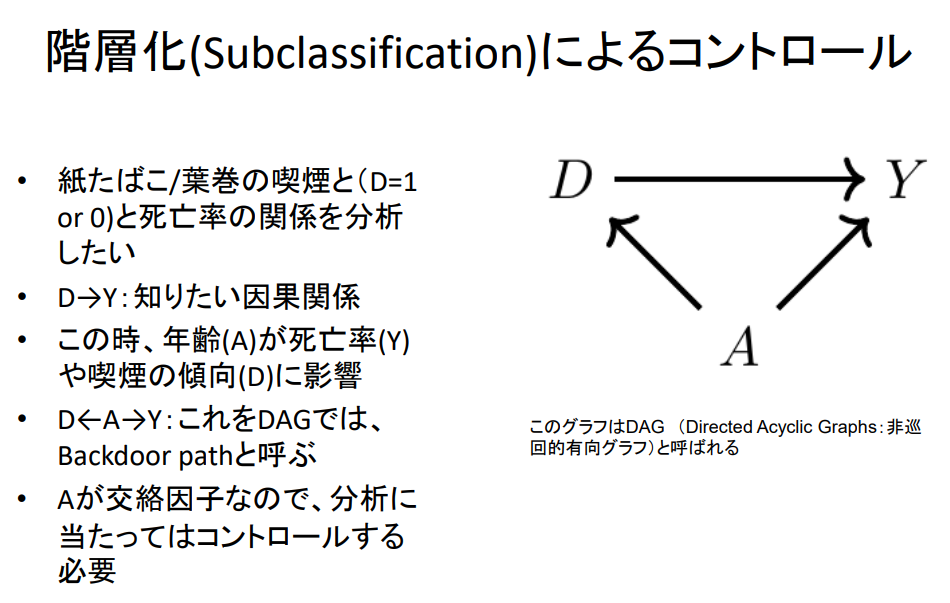
계층화(Subclassification)에 의한 통제
- 샘플을 연령에 따라 3개로 분할(=계층화)하여 각 하위 샘플별로 비교한다.
→ 모든 그룹에서 종이책이 사망률이 더 높다. - 앞의 표를 연령별 이용자 비율로 가중 평균하면
종이담배 : 0.4 × 4% + 0.3 × 8% + 0.3 × 30% = 4.09%
시가 : 0.1 × 2% + 0.3 × 6% + 0.6 × 25% = 2.15%

매칭
- 다음 절차를 매칭(matching)이라고 한다.
1) 처리군에 5개 단위(5개 기업), 통제군에 8개 단위(8개 기업)
2) 처리군에 포함된 단위(표본 내 각 기업 등) 하나하나에 대해
각각 공변량(통제에 사용하는 변수)이 일치하는 단위를 대조군으로부터 선택하여 이를 반사실로 채택한다.
3) 대조군이 처리군보다 단위 수가 많기 때문에 공변량이 정확히 일치하는 단위를 처리군으로부터 선택하지 못할 가능성

4) 정확히 일치하는 공변량을 찾을 수 없는 경우, 공변량이 '가장 가까운' 단위를 반사실로 채택한다.
5) 매칭된 각각의 조합에 대해 두 가지 잠재적 결과의 차이를 취한다.
6) 5쌍의 차이의 평균을 취하면 평균 치료효과(ATE: average treatment effect)를 계산할 수 있다.
7) 치료군과 대조군 사이에는 매칭에 사용된 공변량에 대해 균형이 맞아야 한다.

예: M&A 성과 측정
- M&A 발표 후 주가, 회계상 이익, 생산성 등을 통해 각 M&A가 바람직한지 평가
1) 이벤트 스터디를 이용한 단기적인 주가 변화
= 주가효과(Wealth Effect)에 의한 검증
2) 36개월 등 장기적인 주가, 회계상 이익(ROA가 3년간 상승했는지), 생산성의 변화 - 핵심은 'M&A가 없었을 경우'의 성과 = 반사실을 어떻게 평가할 것인가?

측정 방법의 예
(1) M&A가 없었다면 얻을 수 있었을 매출액 증가율(=반사실)을 계산
(2) 실제 기업 통합 후의 매출액 증가율 계산
→ (1)과 (2)의 차이가 M&A로 인해 발생한 '시너지' 효과라고 생각한다.
- 반사실인 (1)은 어떻게 측정하면 좋을까?

M&A를 실시하지 않았다면 발생했을 매출 예측
Ghosh,A.(2001) 기업 인수 후 운영 성과가 실제로 향상됩니까?, 기업 금융 저널.
- 인수 전 '성과'와 '규모'를 공변량으로 선택
→ '가까운 값'을 취하는 기업을 통제군으로 사용하여 분석한다. - 이 방법은 다음 논문에서 제안되었다.
Barber, B.M., Lyon, J.D., (1996) 비정상적인 운영 성과 감지 : 경험적 힘과 테스트 통계의 사양. 금융 경제학 저널 41, 359-399.
Loughran, T., Ritter, J.R., (1997) 노련한 주식 공모를 실시하는 기업의 운영 성과. Journal of Finance 52, 1823-1850.

M&A를 실시하지 않았더라면 발생했을 매출 예측
- 1단계 : M&A를 실시한 기업(인수기업, 대상기업)과 같은 업종 의 기업군을 M&A 실시 전년도 샘플에서 추출
- 2단계 : 각 샘플 기업의 '총자산 규모에 대해 25% 에서 200% 범위에 속하는' 기업 추출
- 3단계 : 3단계에서 추출한 기업 중 샘플기업과 현금흐름 규모가 가장 가까운 기업을 추출한다.
※ 현금흐름 = 매출액에서 매출원가에서 판매비와 관리비를 차감하고 감가상각비와 영업권 상각비를 뺀 값

M&A를 하지 않았더라면 발생했을 매출 예측
- 4단계 : M&A 전 과 M&A 후 의 성과지표 비교
M&A 실시 기업(처리군)의 M&A 전과 M&A 후의 매출 성장률 합계
MATₜ₊ₙ = SBₜ₊ₙ + STₜ₊ₙ M&A 후
MATₜ₋ₙ = SBₜ₋ₙ + STₜ₋ₙ M&A 전
대조군의 M&A 전과 후의 매출 성장률 합계
MACₜ₊ₙ = S'Bₜ₊ₙ + S'Tₜ₊ₙ M&A 후
MACₜ₋ₙ = S'Bₜ₋ₙ + S'Tₜ₋ₙ M&A 전

M&A를 실시하지 않았다면 발생했을 매출 예측
- M&A를 통한 실적 개선 효과는 다음과 같은 공식으로 평가할 수 있다.
| △Salesgrowth = | ( MAT - MAC ) ₜ₊ₙ | - ( MAT - MAC ) ₜ₋ₙ |
| M&A 후의 실적 차이 | M&A 전의 실적 차이 |

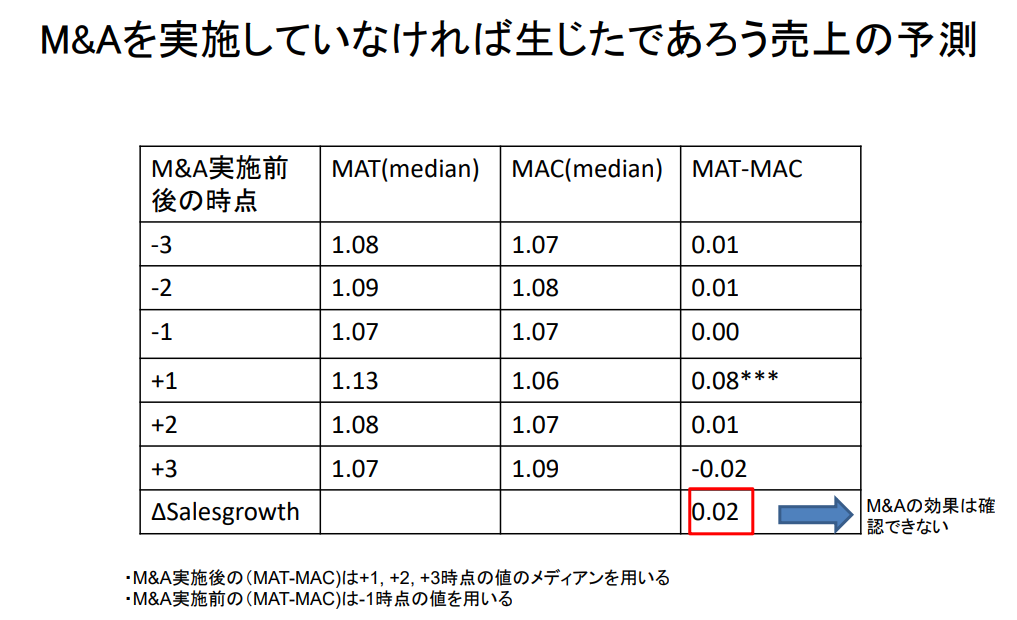
M&A를 실시하지 않았다면 발생했을 매출 예측
| M&A실시 전후 시점 |
MAT(median) | MAC(median) | MAT-MAC |
| -3 | 1.08 | 1.07 | 0.01 |
| -2 | 1.09 | 1.08 | 0.01 |
| -1 | 1.07 | 1.07 | 0.00 |
| +1 | 1.13 | 1.06 | 0.08*** |
| +2 | 1.08 | 1.07 | 0.01 |
| +3 | 1.07 | 1.09 | -0.02 |
| △Salesgrowth | 0.02 | ||
| → M&A의 효과는 확인되지 않음 | |||
- M&A 실시 후 ( MAT - MAC ) 는 +1, +2, +3 시점의 값의 중간값을 사용함.
- M&A 실시 전 ( MAT - MAC ) 은 -1 시점의 값을 사용함.
성향 점수 매칭 ( Propensity Score Matching )
- 다음으로, 여러 공변량을 기반으로 매칭하는 대신, 그 공변량으로부터
'성향 점수(propensity score)'라는 하나의 지표를 예측하고, 그 예측값을 이용하여 매칭하는 방법을 소개합니다.
→ 성향 점수는 하나의 수치이기 때문에 여러 공변량으로 매칭하는 것보다 간단하다. - 성향 점수를 계산하는데 있어 로짓 / 프로빗 모델을 이용한다.
- 경향점수 매칭으로 매칭 샘플을 생성하고, 이를 이용하여 회귀분석 등을 수행한다.

성향 점수 매칭
- '개입'을 받은 그룹 = 치료군
- '개입'을 받지 않은 그룹 = 대조군
- 처리군과 비슷한 '성향 점수'를 가진 표본을 대조군에서 찾아 짝을 짓는다.
- 성향 점수란 '치료군에 들어갈 확률' 혹은 '개입'이 이루어질 확률을 의미한다.
- 성향 점수를 이용한 분석은 개입이 이루어진 메커니즘에 주목하여
개입군과 비개입군의 성격을 비슷하게 만드는 조작을 하는 것

성향 점수 매칭
- 성향 점수의 절차는 다음과 같다.
1) 치료군에 들어가는 샘플에 1, 대조군에 들어가는 샘플에 0을 부여하는 더미변수를 만들어 이를 피설명변수로 한다.
2) 치료군에 들어갈 가능성에 영향을 미치는 요인(=공변량)을 설명변수로 한다.
3) 성향 점수를 로짓 또는 프로빗 모델을 이용하여 산정한다.
4) 성향 점수에 따라 치료군과 대조군을 매칭한다.

성향 점수 매칭 사용법
- 스마트폰 게임을 운영하는 기업이 인지도와 이용률을 높이기 위해 TV 광고를 집행하는 경우,
광고의 효과 검증을 실시합니다. - CM의 효과로 '게임 이용 시간'을 이용한다.
- 특정 2주 동안 CM을 접한 경우 Z = 1
특정 2주 동안 CM을 접하지 않은 경우 Z = 0 - 주당 이용시간을 조사한 결과 변수는 다음과 같다,
Y1: TV광고를 본 사람의 게임 이용 시간
Y0: TV광고를 보지 않은 사람의 게임 이용 시간
출처) 호시노 다카히로「통계적 인과효과의 기초」岩波データサイエンスVol.3, 62-89, 2016년

단순 평균의 차이
- CM의 효과 지표로
"CM 접촉군 이용시간의 평균"
과
'CM 비접촉군 이용시간의 평균'
의 단순한 차이를 사용하는 것은 바람직하지 않다.

단순 평균의 차이
- 단순 차이를 인과관계로 계산하면 '광고를 보여주면 앱을 사용하지 않게 된다'는 결과가 나올 가능성
이유: 광고를 접한 사람( Z = 1 )은 TV 시청시간이 길고, 연령이 높기 때문에 스마트폰에서 앱 이용 빈도가 낮은 경향
→ Self-Selection Bias의 문제 - 치료군 ( Z = 1 )과 대조군 ( Z = 0 ) 간 차이가 있는 변수(예: TV 시청시간) 중
결과(앱 이용시간)에 영향을 미치는 변수(공변량)의 영향력 제거 필요
→ 매칭을 통해 공변량이 균형을 이루도록 한다.

| 처리군 | 대조군 | |||||||
| ID | 1 | 2 | 3 | ... | 1001 | 1002 | 1003 | |
| Z값 | 1 | 1 | 1 | ... | 0 | 0 | 0 | |
| 공변량 | TV시청시간/일 | 4.1 | 2.2 | 3.2 | ... | 1.8 | 3.1 | 0.5 |
| 연령 | 31 | 28 | 51 | ... | 29 | 31 | 37 | |
| 성별 | 여성 | 남성 | 여성 | ... | 남성 | 여성 | 남성 | |
| 지역 | 관동 | 관동 | 경한신 | ... | 경한신 | 관동 | 동해 | |
| 자녀유무 | 무 | 유 | 유 | ... | 무 | 무 | 유 | |
| 수입 | 320 | 529 | 419 | ... | 608 | 308 | 720 | |
| 성향점수 | 0.8 | 0.2 | 0.7 | ... | 0.2 | 0.8 | 0.1 |
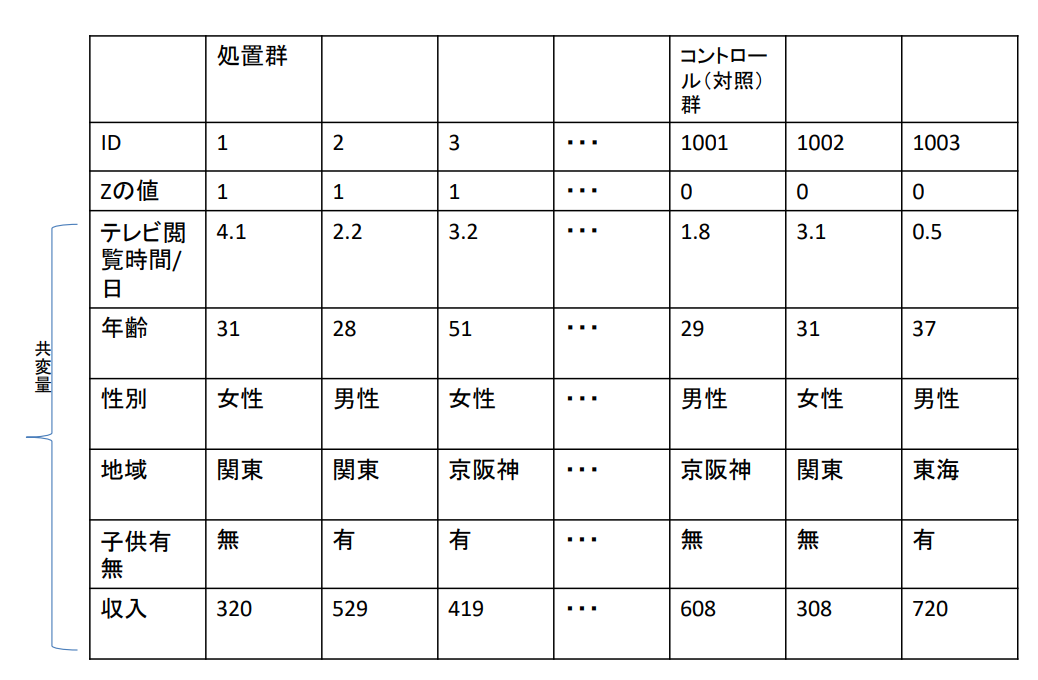
성향 점수를 이용한 매칭
- 공변량별로 매칭하는 방법(다음 주 논의)은 공변량의 수가 많아지면 어렵다.
- 성향 점수 값으로 매칭하면 성향 점수는 1차원이므로 공변량을 그대로 사용하는 것보다 매칭이 쉬워진다.
- 공변량으로 사용할 변수 선택 방법
1) 결과(잠재적 결과 변수)에 대한 예측력이 높은 변수를 이용한다.
2) Z = 1의 집단과 Z = 0의 집단에서 분포가 다른(평균 등이 다른) 변수를 이용한다.

| 처리군 | 대조군 | |||||||
| ID | 1 | 2 | 3 | ... | 1001 | 1002 | 1003 | |
| Z값 | 1 | 1 | 1 | ... | 0 | 0 | 0 | |
| 공변량 | TV시청시간/일 | 4.1 | 2.2 | 3.2 | ... | 1.8 | 3.1 | 0.5 |
| 연령 | 31 | 28 | 51 | ... | 29 | 31 | 37 | |
| 성별 | 여성 | 남성 | 여성 | ... | 남성 | 여성 | 남성 | |
| 지역 | 관동 | 관동 | 경한신 | ... | 경한신 | 관동 | 동해 | |
| 자녀유무 | 무 | 유 | 유 | ... | 무 | 무 | 유 | |
| 수입 | 320 | 529 | 419 | ... | 608 | 308 | 720 | |
| 성향점수 | 0.8 | 0.2 | 0.7 | ... | 0.2 | 0.8 | 0.1 |
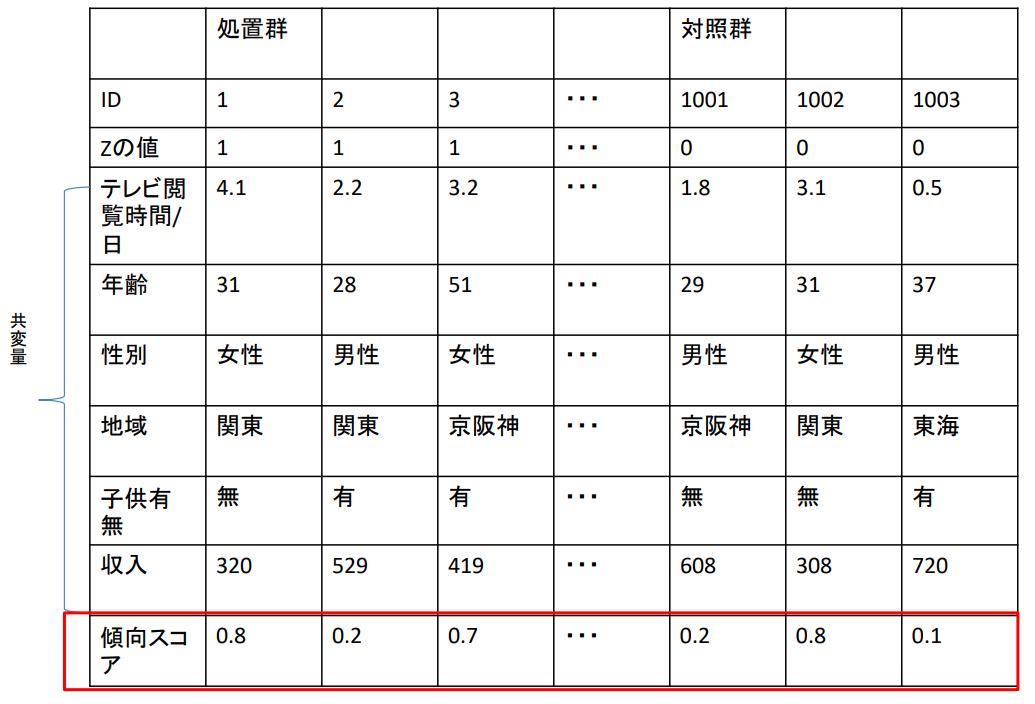
R을 이용한 경향 점수 매칭
- MatchIt 패키지를 사용하여 경향성 점수 매칭을 수행하는 방법을 소개합니다.
#install.packages ( " MatchIt " )
library ( MatchIt )
특히 '최근접 매칭'을 통해 ATE(Average Treatment Effect: 평균 치료 효과)를 추정하는 방법을 소개합니다.


R을 이용한 성향 점수 매칭
- 데이터는
data ( lalonde )
- Dehejia and Wahba (1999)에서 사용된 직업훈련과 이후 임금의 관계를
성향점수 매칭으로 검증하기 위한 데이터입니다.
데헤지아, 라지브, 사덱 와바. 1999. 비실험적 연구에서의 인과적 효과:
교육 프로그램 평가의 재평가.미국 통계 학회지 94 (448): 1053-1062.

Dehejia and Wahba (1999)
- 각 데이터 항목은
표본 수는 445개, 변수는 12개이다.
age: 나이
educ: 교육연수
race: 인종
nodegree: 샘플의 고졸 여부
married: 샘플이 기혼자

Dehejia and Wahba (1999)
- 각 데이터 항목은
re74 : 1974년 실질소득
re75 : 1975년 실질소득
re78 : 1978년 실질소득
u74 : 1974년 실질소득이면 1, 그렇지 않으면 0을 부여하는 더미변수
u75 : 1975년 실질소득이면 1, 그렇지 않으면 0을 부여하는 더미변수
treat : 치료군이면 1을 부여하는 더미변수 ( 1 or 0 )
→ 교육훈련을 받고 있는 표본이 처리군

치료군과 대조군 비교
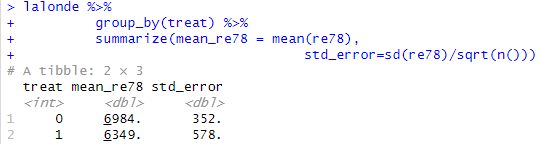
- 매칭을 하기 전에 치료군과 대조군의 1978년 실질소득을 비교한다.
lalonde %>%
group_by ( treat ) %>%
summarise ( mean_re78 = mean ( re78 ) ,
std_error = sd ( re78 ) / sqrt ( n ( ) ) )

치료군과 대조군 비교
- 매칭을 하기 전에 치료군과 대조군의 1978년 실질소득을 비교한다.
# A tibble: 2 x 3
treat mean_re78 std_error
<int> <dbl> <dbl>
1 0 6984. 352.
2 1 6349. 578.
t검정을 하면
with ( lalonde , t.test ( re78 ~ treat ) )
t = 0.93773, p-value = 0.3491
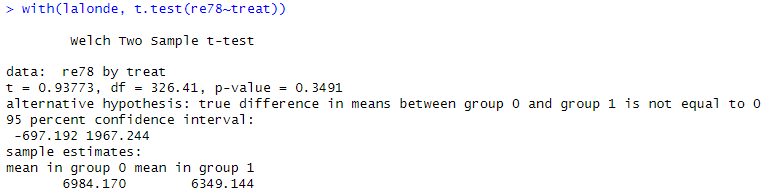


치료군과 대조군 비교
- 사용하는 공변량(covarites)에 대해 매칭 전에 차이가 있는지 확인해야 합니다.
- 예를 들어, 연령에 차이가 있는지
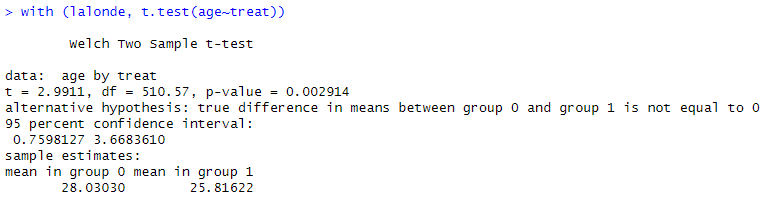
with ( lalonde , t.test ( age ~ treat ) )

R을 이용한 스코어 측정
웰치 투 샘플 t-검증
데이터: 치료별 연령
t = 2.9911, df = 510.57, p-값 = 0.002914
대안 가설: 실제 평균 차이는 다음과 같지 않음 0과 같지 않음
95퍼센트 신뢰 구간:
0.7598127 3.6683610
표본 추정치
그룹 0의 평균 그룹 1의 평균
28.03030 25.81622


최근접 매칭
- 성향 점수의 차이가 가장 작은 샘플끼리 매칭하는 방법은
'최근접 매칭(nearest-neighbor matching)' - 차이가 0인 경우에만 일치하는 것은 'exact matching'

최근접 매칭
가장 가까운 이웃 매칭
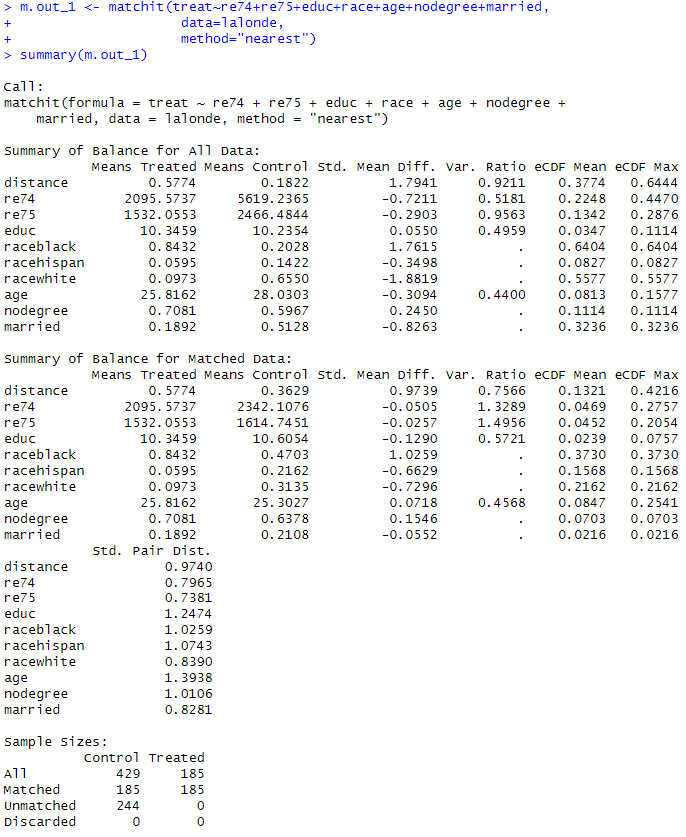
m.out_1 <- matchit ( treat ~ re74 + re75 + educ + race + age + nodegree + married,
data = lalonde ,
method = " nearest " )
treat = 1 or 0
결과 보기
summary(m.out_1)


최근접 매칭
Sample sizes:
| Control | Treated | |
| All | 429 | 185 |
| Matched | 185 | 185 |
| Unmatched | 244 | 0 |
| Discarded | 0 | 0 |


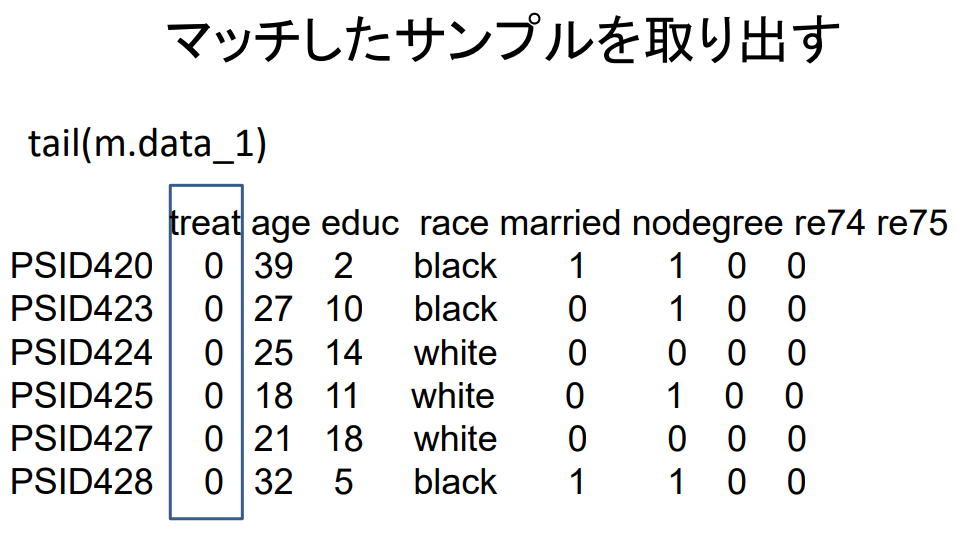
일치하는 샘플을 꺼내기
일치하는 샘플을 추출하려면
m.data_1 <- match.data ( m.out_1 )
match.data 함수를 사용하면 된다.

일치하는 샘플을 꺼내기
head ( m.data_1 )
| treat | age | educ | race | married | nodegree | re74 | re75 | |
| NSW1 | 1 | 37 | 11 | black | 1 | 1 | 0 | 0 |
| NSW2 | 1 | 22 | 9 | hispan | 0 | 1 | 0 | 0 |
| NSW3 | 1 | 30 | 12 | black | 0 | 0 | 0 | 0 |
| NSW4 | 1 | 27 | 11 | black | 0 | 1 | 0 | 0 |
| NSW5 | 1 | 33 | 8 | black | 0 | 1 | 0 | 0 |
| NSW6 | 1 | 22 | 9 | black | 0 | 1 | 0 | 0 |



일치하는 샘플을 꺼내기
| treat | age | educ | race | married | nodegree | re74 | re75 | |
| PSID420 | 0 | 39 | 2 | black | 1 | 1 | 0 | 0 |
| PSID423 | 0 | 27 | 10 | black | 0 | 1 | 0 | 0 |
| PSID424 | 0 | 25 | 14 | white | 0 | 0 | 0 | 0 |
| PSID425 | 0 | 18 | 11 | white | 0 | 1 | 0 | 0 |
| PSID427 | 0 | 21 | 18 | white | 0 | 0 | 0 | 0 |
| PSID428 | 0 | 32 | 5 | black | 1 | 1 | 0 | 0 |

매칭된 샘플 추출
- 매칭된 처리군과 대조군을 CSV 파일로 추출
write.table ( m.data_1 , file = " m.data_1.csv " , sep = " , " )

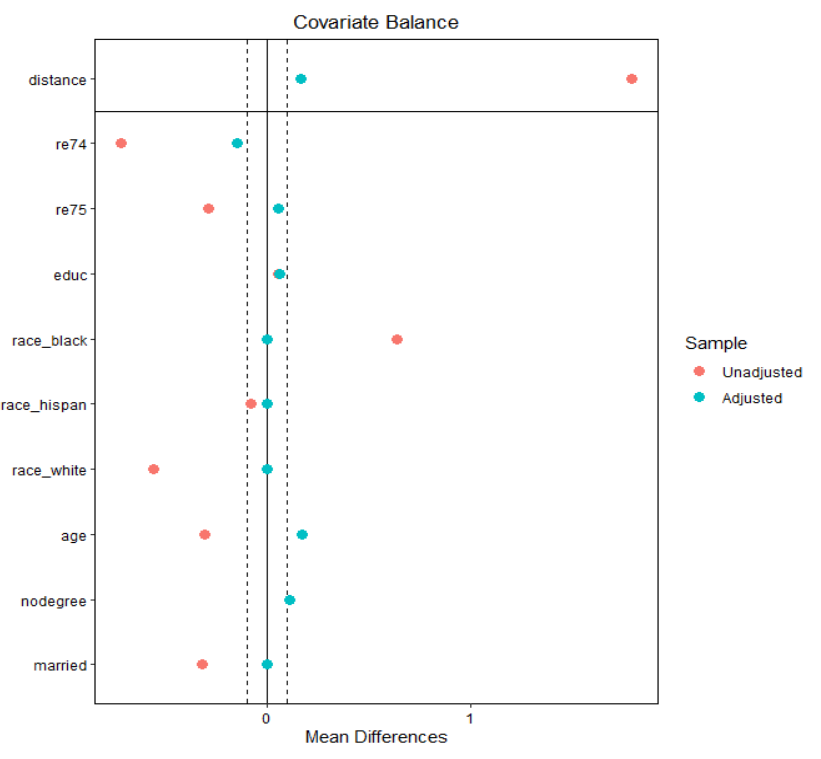
더 나은 성향 점수란?
- 좋은 성향 점수를 얻기 위해서는 매칭 후 데이터에서 공변량의 균형이 잘 잡혀있는지가 중요합니다.
- 공변량의 균형이 잘 잡혀 있는지 확인하기 위해서는 공변량의 평균이 가까운지 확인하는 것이 중요합니다.
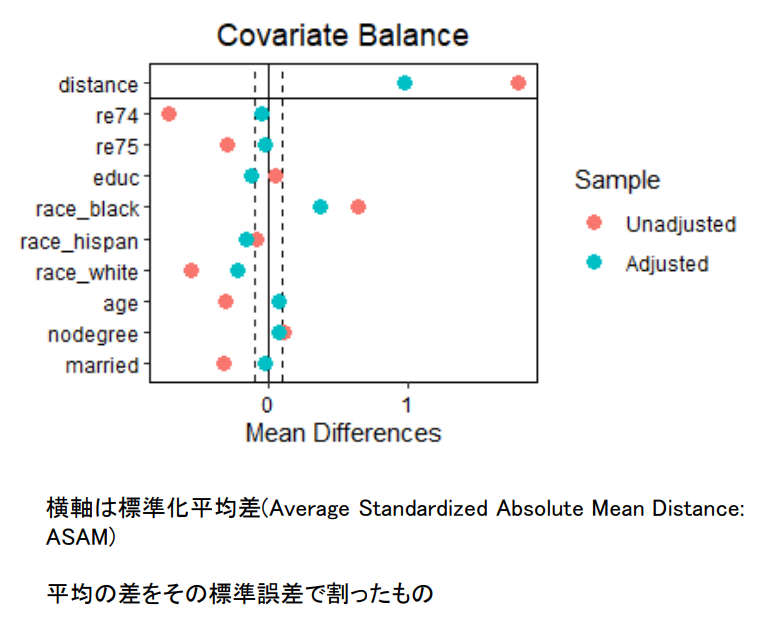
- 공변량의 균형을 시각화해주는 cobalt 패키지의 love.plot()을 사용하여 공변량의 균형을 확인한다.

공변량 균형 시각화
# install.packages ( " cobalt " )
library ( cobalt )
love.plot ( m.out_1 , threshold =.1 )

공변량 균형
가로축은 표준화 평균차(Average Standardized Absolute Mean Distance:ASAM)
평균의 차이를 그 표준오차로 나눈 것.
매칭 전 샘플을 사용하여 회귀분석을 수행합니다.
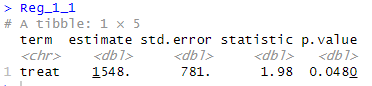
Reg_1_1 <- lalonde % > %
lm ( data= . ,
re78 ~ treat + re74 + re75 + educ + race + age + nodegree + married ) % > %
tidy ( ) % > %
filter ( term == " treat " )
Reg_1_1



매칭 후 샘플을 사용하여 회귀분석을 수행합니다.
- 이미 매칭이 끝났기 때문에 통제변수는 필요 없다.
PSM_m.out_1 <- lm ( data = m.data_1 ,
formula = re78 ~ treat ) %>%
tidy ( )
PSM_m.out_1

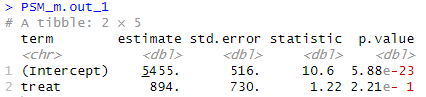

두 결과를 비교하면
- 매칭 전:
term estimate std.error statistic p.value treat 1548. 781. 1.98 0.0480
- 매칭 후:
term estimate std.error statistic p.value treat 894. 730. 1.22 2.21e-1

최근접 매칭
- '최근접 매칭'의 경우, 두 샘플 간의 거리에 제한이 없다.
- 그래서 추가적인 조건으로 거리가 일정 범위 내에 있을 것을 요구한다.
- 이 ε (범위) 를 caliper라고 한다.

최근접 매칭
- Caliper 설정 예: caliper = .25
- 성향점수(PS)에 대해 완전히 일치하거나 0.25 표준편차 이내로 일치할 수 있다.
- 샘플이 없는 경우, 대조군 샘플에서 떨어뜨린다.

최근접 매칭
- 두 샘플 사이의 거리에 일정한 제한을 추가합니다.
→ caliper = 0.25 의 조건에서 최근접 매칭을 수행한다.
m.out_2 <- matchit ( treat ~ re74 + re75 + educ + race + age + nodegrㄷㄷ + married ,
data = lalonde,
method = " nearest " ,
caliper = 0.25 )


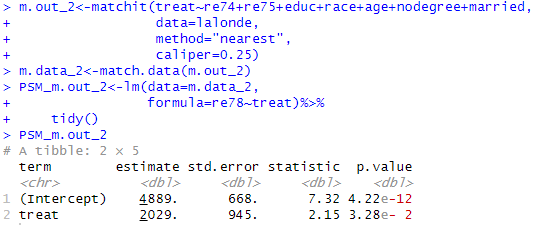
두 결과를 비교하면
- 매칭 전:
term estimate std.error statistic p.value treat 1548. 781. 1.98 0.0480 - 매칭 후:
term estimate std.error statistic p.value treat 2029. 945. 2.15 3.28e-2


최근접 매칭을 수행한다.
- 두 샘플 사이의 거리에 일정한 제한을 추가합니다.
→ caliper = 0.25 및 exact = " married " 조건에서 최근접 매칭을 수행한다.
m.out_3 <- matchit ( treat ~ re74 + re75 + educ + race + age + nodegree + married ,
data = lalonde ,
method = " nearest " ,
caliper = 0.25 ,
exact = " married " )

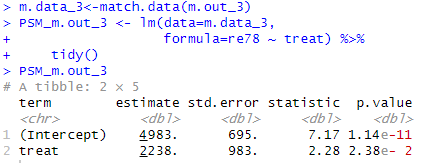

두 결과를 비교하면
- 매칭 전:
term estimate std.error statistic p.value treat 1548. 781. 1.98 0.0480 - 매칭 후:
term estimate std.error statistic p.value treat 2238. 983. 2.28 2.38e-2

공변수 균형

다음
- 매칭(2)
- 성향점수를 사용하지 않는 매칭
- 복원 매칭과 비복원 매칭

'WBS - 2023 Fall > 기업경제학 연습' 카테고리의 다른 글
| (기업경제 #11) 불연속 회귀의 개념 (0) | 2023.12.21 |
|---|---|
| (기업경제 #10) 성향 점수를 사용하지 않는 매칭 | 복원 매칭과 비복원 매칭 (0) | 2023.12.14 |
| (기업경제 #8) 로지트 모델(Logit Model)과 프로빗 모델(Probit Model) (0) | 2023.11.29 |
| (기업경제 #7) DID | Difference-in-Difference (차이의 차이 분석) (0) | 2023.11.16 |
| (기업경제 #6) 패널 분석 (Panel data analysis) (0) | 2023.11.09 |
| (기업경제 #5) 더미 변수를 이용한 분석 (0) | 2023.11.02 |
| (기업경제 #4) 이상치 처리 | 선형 회귀 모델(2) (0) | 2023.10.26 |
| (기업경제 #3) 선형회귀 Model (0) | 2023.10.19 |



